第三章作业
计算AlexNet、VGG19、ResNet152三个网络中的神经元数目及可训练的参数数目
AlexNet
proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf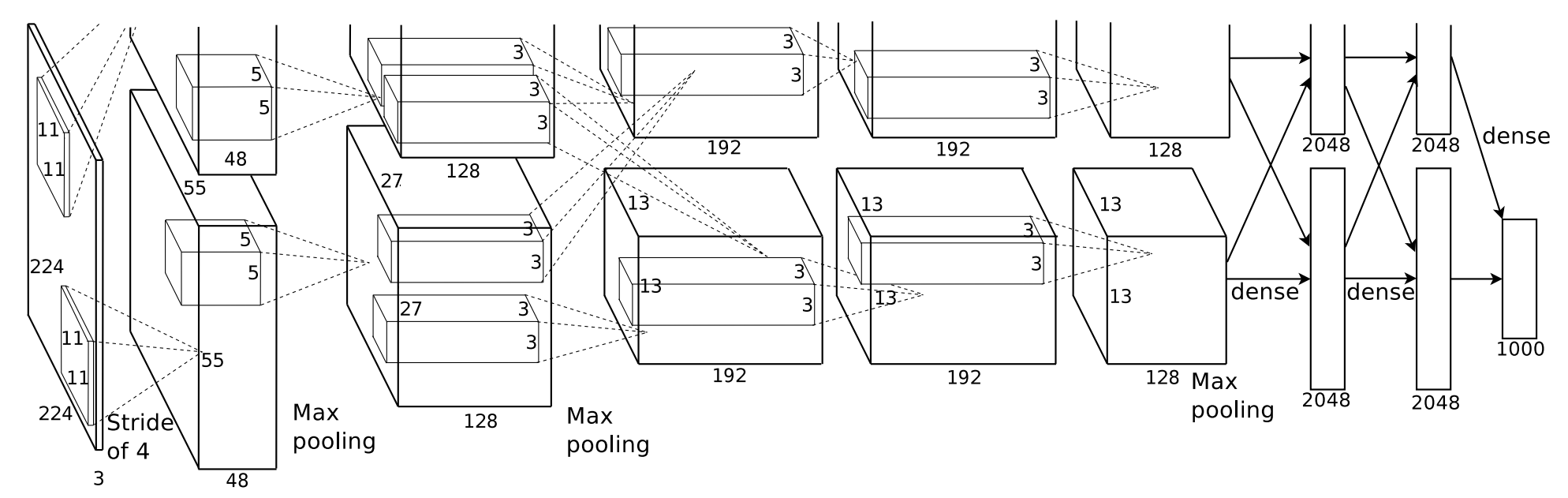
根据论文中给出的网络结构
AlexNet共有五层卷积层和三层全连接层
其中第一层卷积层有96个卷积核,3通道,大小为11×11,步长为4
第二层卷积层有256个卷积核,48通道,大小为5×5
第三次卷积层有384个卷积核,256通道,大小为3×3
第四层卷积层有384个卷积核,192通道,大小为3×3
第五层卷积层有256个卷积核,192通道,大小为3×3
三层全连接层的神经元数量分别为4096、4096、1000
神经元数目:
每个卷积层的神经元数目为feature map大小
55* 55* 96+ 27* 27* 256+ 13* 13* 384+13* 13* 384+13* 13* 256+4096+4096+1000 = 659272
可训练参数数目:34848+307200+884736+663552+442368+ 6* 6* 256* 4096+4096* 4096+4096* 1000 = 60954656
VGG19
卷积层1-2:64个3x3的卷积核
卷积层3-4:128个3x3的卷积核
卷积层5-8:256个3x3的卷积核
卷积层9-12:512个3x3的卷积核
卷积层13-16:512个3x3的卷积核
全连接层1:输入神经元数量为 7x7x512,输出神经元数量为 4096
全连接层2:输入神经元数量为 4096,输出神经元数量为 4096
全连接层3(输出层):输入神经元数量为 4096,输出神经元数量为类别数(通常为1000)
参数数量: 3584 + 147712 + 590336 + 2360320 + 4719616 + 102764544 + 16781312 + 4097000 = 138,357,104
总神经元数量 = (3,161,600 * 2) + (1,605,632 * 2) + (802,816 * 4) + (401,408 * 4) + (100,352 * 4) + 4096 + 4096 + 1000 = 64,614,528
ResNet152
由于网络的参数数量过于庞大,引入torchinfo库协助计算
1 | |
得到的结果如下:
1 | |
全连接层神经元数量计算过程:
- 全连接层1:4096个神经元
- 全连接层2:4096个神经元
- 全连接层3(输出层):1000个神经元(如果用于ImageNet分类任务)
现在,考虑到一些层的输出特征图大小相同,我们将每组卷积层的神经元数量乘以相应的层数,然后将所有层的神经元数量相加。
总神经元数量 = (3,161,600 * 2) + (1,605,632 * 2) + (802,816 * 4) + (401,408 * 4) + (100,352 * 4) + 4096 + 4096 + 1000 = 64,614,528 个神经元
简述错误率与IoU、mAP的关系
错误率是指分类或检测模型在执行特定任务时所犯的错误百分比
IoU即交并比,是指检测框与真实框的交集面积与并集面积之比
mAP中文翻译过来叫做平均精度均值,其中AP为平均精度(Average Precision),mAP是把每个类别的AP都单独拿出来,然后计算所有类别AP的平均值,代表着对检测到的目标平均精度的一个综合评价
错误率是用于衡量模型性能的一种最简单的指标,反应的是一个大致的情况。IoU和mAP则是度量模型性能更详细的指标,其中mAP使用了IoU的概念,提供了一个比IoU更全面的度量方式
简述R-CNN、Fast R-CNN和 Faster R-CNN 的区别
R-CNN 是一种基于区域建议的目标检测方法,对每个候选区域独立地进行卷积特征提取,速度比较慢。
Fast R-CNN 通过在整个图像上运行卷积网络,然后在提取的特征图上选择感兴趣的区域(RoI,Region of Interest)来改进 R-CNN。不同于 R-CNN 中独立处理每个候选区域,Fast R-CNN 在整个图像上运行卷积网络一次,然后通过RoI池化层将每个区域映射到卷积特征图上。特征提取是在整个图像上进行的,而不是独立处理每个区域,这样做可以加快速度。
Faster R-CNN 是进一步改进的方法,引入了RPN(Region Proposal Network)来生成候选区域。RPN是一个用于在图像中生成区域建议的神经网络,与整个检测网络(如Fast R-CNN)共享卷积层。这样就可以利用RPN直接从特征图中生成候选框,不再需要独立的区域提议步骤。
简述LSTM标准模型中三个门的主要作用,并给出计算公式
遗忘门
主要作用是决定哪些信息应该被忘记或丢弃。它通过一个sigmoid激活函数来输出一个0到1之间的值,表示每个记忆单元中信息保留的程度。当遗忘门输出接近1时,表示保留所有信息;当接近0时,表示尽可能忘记先前的信息。
$$\boldsymbol{f}^{(t)}=\sigma\left(U^{f} \boldsymbol{x}^{(t)}+W^{f} \boldsymbol{h}^{(t-1)}+\boldsymbol{b}^{f}\right)=\sigma\left(\mathcal{W}_{f}\left(\begin{array}{l}
\boldsymbol{h}^{(t-1)} \
\boldsymbol{x}^{(t)}
\end{array}\right)\right)$$
输入门
控制新信息的输入程度。通过sigmoid激活函数和tanh激活函数来筛选和创建新的候选值,然后将其结合起来更新单元的状态。
$$\boldsymbol{i}^{(t)}=\sigma\left(U^{i} \boldsymbol{x}^{(t)}+W^{i} \boldsymbol{h}^{(t-1)}+\boldsymbol{b}^{i}\right)=\sigma\left(\mathcal{W}_{i}\left(\begin{array}{l}
\boldsymbol{h}^{(t-1)} \
\boldsymbol{x}^{(t)}
\end{array}\right)\right)$$
输出门
决定当前时刻的隐藏状态应该输出多少信息。它根据当前的输入和前一时刻的隐藏状态,结合记忆单元的状态,输出一个0到1之间的值。
$$\boldsymbol{g}^{(t)}=\sigma\left(U^{o} \boldsymbol{x}^{(t)}+W^{o} \boldsymbol{h}^{(t-1)}+\boldsymbol{b}^{o}\right)=\sigma\left(\mathcal{W}_{o}\left(\begin{array}{l}
\boldsymbol{h}^{(t)} \
\boldsymbol{x}^{(t)}
\end{array}\right)\right)$$
简述GAN的训练过程
模型由两部分组成:
- 生成器:生成器的任务是生成与真实数据相似的虚假数据,目标是让生成器尽可能地欺骗判别器,使其生成的数据在视觉上或在数据分布上与真实数据难以区分。
- 判别器:判别器是一个二分类器,它的任务是将真实数据和由生成器产生的假数据区分开来。判别器的目标是尽可能地准确地区分真实数据和虚假数据。
生成器生成一批假样本,然后将这些假样本输入给判别器,判别器评估并给出对这些样本的判断,判别器接收一批真实样本和由生成器生成的假样本,然后分别对它们进行分类。
优化判别器:$$J^{(D)}=-\mathrm{E}{\boldsymbol{x} \sim p{\text {data }}(\boldsymbol{x})}[\log (D(\boldsymbol{x}))]-\mathrm{E}{z \sim p{\boldsymbol{z}}(z)}[\log (1-D(G(\boldsymbol{z})))]$$
优化生成器:$$J^{(G)}=\mathrm{E}{\boldsymbol{z} \sim p{z}(z)}[\log (1-D(G(z)))]$$