A6分析与简答
A6.1 (5分) 分析卷积神经网络中用1×1的卷积核的作用。
- 改变通道数
当卷积核的个数大于或小于输入通道数时,可以改变输出的通道数 - 增加非线性
1x1卷积核可以在不改变特征维度的情况下添加非线性激活
A6.2 (5分) 计算函数$𝑦 = max(𝑥_1,⋯,𝑥_𝐷)$和函数$𝑦 = argmax(𝑥_1,⋯,𝑥_𝐷)$的梯度。
$𝑦 = max(𝑥_1,⋯,𝑥_𝐷)$:如果对于输入向量中的某个元素$𝑥_𝑖$,它是最大值,则其梯度为1,其他所有元素的梯度都为0。用数学符号表示为
$$
\frac{\partial y}{\partial x_{i}}=\left{\begin{array}{ll}
1, & \text { if } x_{i}=max(𝑥_1,⋯,𝑥_𝐷) \
0, & \text { otherwise }
\end{array}\right.
$$
argmax(𝑥_1,⋯,𝑥_𝐷)输出的是使得函数取得最大值的元素的索引位置.如果对于输入向量中的某个元素𝑥𝑖,它的索引位置与最大值所在的位置相同,则其梯度为1,其他所有元素的梯度都为0。用数学符号表示为
$$
\frac{\partial y}{\partial x_{i}}=\left{\begin{array}{ll}
1, & \text { if } i=argmax(𝑥_1,⋯,𝑥_𝐷) \
0, & \text { otherwise }
\end{array}\right.
$$
A6.3 (5分) 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果。
[[循环神经网络#长短时记忆网络(LSTM)]]
LSTM - 长短期记忆递归神经网络 - 知乎
Fetching Title#6dum
遗忘门
$$f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)$$
记忆门
$$\begin{array}{l}
i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \
\widetilde{C}{t}=\tanh \left(W{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right) \
\end{array}$$
输出门
$$\begin{array}{l}
o_{t}=\sigma\left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right.) \
h_{t}=o_{t} * \tanh \left(C_{t}\right)
\end{array}$$
单元状态更新
$$C_{t}=f_{t} * C_{t-1}+i_{t} * \widetilde{C_{t}}$$
对于参数$W_i$, $W_f$,$W_o$, 统一用$W$表示:
$$\frac{\partial L_{t}}{\partial W}=\frac{\partial L_{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial C_{t}} * \ldots *\left(\prod_{k=2}^{t} \frac{\partial C_{k}}{\partial C_{k-1}}\right) * \frac{\partial C_{1}}{\partial W}$$
LSTM 通过记忆单元 C 来缓解梯度消失问题。针对 $\frac{\partial C^{(k)}}{\partial C^{(k-1)}}$ 求得,
$$
\begin{aligned}
\frac{\partial C^{(k)}}{\partial C^{(k-1)}}= & \frac{\partial C^{(k)}}{\partial f^{(k)}} \frac{\partial f^{(k)}}{\partial h^{(k-1)}} \frac{\partial h^{(k-1)}}{\partial C^{(k-1)}}+\frac{\partial C^{(k)}}{\partial i^{(k)}} \frac{\partial i^{(k)}}{\partial h^{(k-1)}} \frac{\partial h^{(k-1)}}{\partial C^{(k-1)}} \
& +\frac{\partial C^{(k)}}{\partial a^{(k)}} \frac{\partial a^{(k)}}{\partial h^{(k-1)}} \frac{\partial h^{(k-1)}}{\partial C^{(k-1)}}
\end{aligned}
$$
具体计算后得到,
$$
\begin{array}{c}
\frac{\partial C^{(k)}}{\partial C^{(k-1)}}=C^{(k-1)} \sigma^{\prime}(\cdot) W_{f} o^{(k-1)} \tanh ^{\prime}\left(C^{(k-1)}\right) \
+a^{(k)} \sigma^{\prime}(\cdot) W_{i} o^{(k-1)} \tanh ^{\prime}\left(C^{(k-1)}\right) \
+i^{(k)} \tanh ^{\prime}(\cdot) W_{c} * o^{(k-1)} \tanh ^{\prime}\left(C^{(k-1)}\right) \
+f^{(t)} \
\prod_{k=t+1}^{T} \frac{\partial C^{(k)}}{\partial C^{(k-1)}}=\left(f^{(k)} f^{(k+1)} \ldots f^{(T)}\right)+\text { other }
\end{array}
$$
在LSTM迭代过程中,针对 $\prod_{k=t+1}^{T} \frac{\partial C^{(k)}}{\partial C^{(k-1)}}$ 而言,每一步 $\frac{\partial C^{(k)}}{\partial C^{(k-1)}}$ 可以自主的选择在 $[0,1]$ 之间,或者大于1,因为 $f^{(k)}$ 是可训练学习的。那么整体 $\prod_{k=t+1}^{T} \frac{\partial C^{(k)}}{\partial C^{(k-1)}}$ 也就不会一直减小,远距离梯度不至于完全消失,也就能够解决RNN中存在的梯度消失问题。
A6.4 (5分) 当将自注意力模型作为神经网络的一层使用时,分析它和卷积层以及循环层在建模长距离依赖关系的效率和计算复杂度方面的差异。
LSTM如何解决RNN带来的梯度消失问题 - 知乎
Transformer/CNN/RNN的对比(时间复杂度,序列操作数,最大路径长度) - 知乎
基于卷积或循环网络的序列编码都是一种局部的编码方式,只建模了输入信息的局部依赖关系.虽然循环网络理论上可以建立长距离依赖关系,但是由于信息传递的容量以及梯度消失问题,实际上也只能建立短距离依赖关系。
RNN梯度消失的原因是,随着梯度的传导,梯度被近距离梯度主导,模型难以学习到远距离的信息。具体原因也就是 $\prod_{k=t+1}^{T} \frac{\partial h^{(k)}}{\partial h^{(k-1)}}$ 部分,在迭代过程中,每一步 $\frac{\partial h^{(k)}}{\partial h^{(k-1)}}$ 始终在 $[0,1]$ 之间或者始终大于1。
因此,卷积层和循环层不适合用于建模长距离依赖关系。
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:
- 增加网络的层数,通过一个深层网络来获取远距离的信息交互
- 使用全连接网络。
而全连接网络无法处理变长序列,自注意力模型可以解决这个问题,因为其连接权重是动态学习的。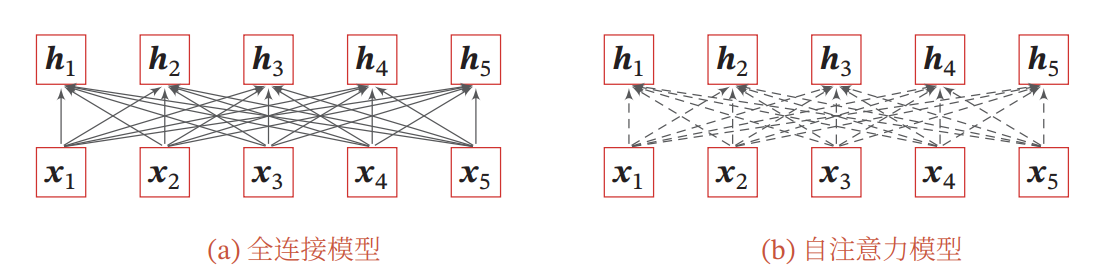
复杂度:
循环层:
$h_{t}=f\left(U x_{t}+W h_{t-1}\right)$
- $U x_{t}: d \times m 与 m \times 1$ 运算,复杂度为 $\mathcal{O}(m d)$ , m为input size
- $W h_{t-1}: d \times d 与 d \times 1$ 运算,复杂度为 $\mathcal{O}\left(d^{2}\right)$
故一次操作的时间复杂度为 $\mathcal{O}\left(d^{2}\right)$ , n次序列操作后的总时间复杂度为 $\mathcal{O}\left(n d^{2}\right)$
卷积层:
注: 这里保证输入输出都是一样的,即均是 $n \times d$
- 为了保证输入和输出在第一个维度都相同,故需要对输入进行padding操作,因为这里kernel size为k, (实际kernel的形状为 $k \times d$ ) 如果不 padding的话,那么输出的第一个维度为 $n-k+1$ ,因为这里stride是为1的。为了保证输入输出相同,则需要对序列的前后分别padding长度为 $(k-1) / 2$ 。
- 大小为 $k \times d$ 的卷积核一次运算的复杂度为: $\mathcal{O}(k d)$ ,一共做了 n 次,故复杂度为 $\mathcal{O}(n k d)$
- 为了保证第二个维度在第二个维度都相同,故需要 d 个卷积核,所以卷积操作总的时间复杂度为 $\mathcal{O}\left(n k d^{2}\right)$
自注意力层:
$A(Q, K, V)={Softmax}\left(Q K^{T}\right)$
- $Q, K, V: n \times d$
- 相似度计算 $Q K^{T}: n \times d 与 d \times n$ 运算,得到 $n \times n$ 矩阵,复杂度为 $\mathcal{O}\left(n^{2} d\right)$
- softmax计算: 对每行做softmax,复杂度为 $\mathcal{O}(n)$ ,则 $\mathrm{n}$ 行的复杂度为 $\mathcal{O}\left(n^{2}\right)$
- 加权和: $n \times n$ 与 $n \times d$ 运算,得到 $n \times d$ 矩阵,复杂度为 $\mathcal{O}\left(n^{2} d\right)$ .故最后self-attention的时间复杂度为 $\mathcal{O}\left(n^{2} d\right)$