基于 Transformer 的命名实体识别
数据介绍
根据train_TAG.txt统计得到的标签集如下: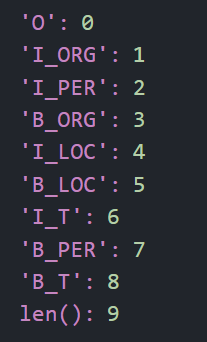
标签集大小为9。
模型框架
模型结构
模型使用hugging face的bert-base-chinese作为预训练模型。模型接受预处理后的字符序列作为输入,输出字符对应的标签。
模型参数
BERT模型包含12层Transformer encoder,每层Transformer encoder包含的多头自注意头数为12,隐藏层大小为768。
在构建数据集时,设定单条文本最大长度为128,对数据集进行阶段或填充。使用库函数BertTokenizer对数据进行向量化操作。
训练时的参数包括:
- 优化器:AdamW
- 学习率:5e-5
- 批次大小:32
- 训练轮数:5
训练算法
训练过程中,模型的输入为编码后的字符序列,输出为每个字符对应的标签。损失函数采用交叉熵损失,优化器为AdamW。训练循环中每个epoch包括以下步骤:
- 前向传播计算损失。
- 反向传播更新模型参数。
- 每个epoch结束后输出损失值。
实验结果
训练过程
每个epoch结束后在扩展集上进行验证,记录扩展集上的损失和准确率。
Epoch 1 - Training Loss: 0.0131668053176951, Validation Loss: 0.010239653369493392, Validation Accuracy: 0.9971221633572501
Epoch 2 - Training Loss: 0.00557029220667432, Validation Loss: 0.009271262560837594, Validation Accuracy: 0.9975453132821626
Epoch 3 - Training Loss: 0.003971861287672002, Validation Loss: 0.010250022615927534, Validation Accuracy: 0.9975541777907558
Epoch 4 - Training Loss: 0.0030227819530087912, Validation Loss: 0.01101609307826279, Validation Accuracy: 0.9976459515267813
Epoch 5 - Training Loss: 0.002555301935822686, Validation Loss: 0.01072908611020737, Validation Accuracy: 0.9976827131653596
训练损失和验证集性能曲线
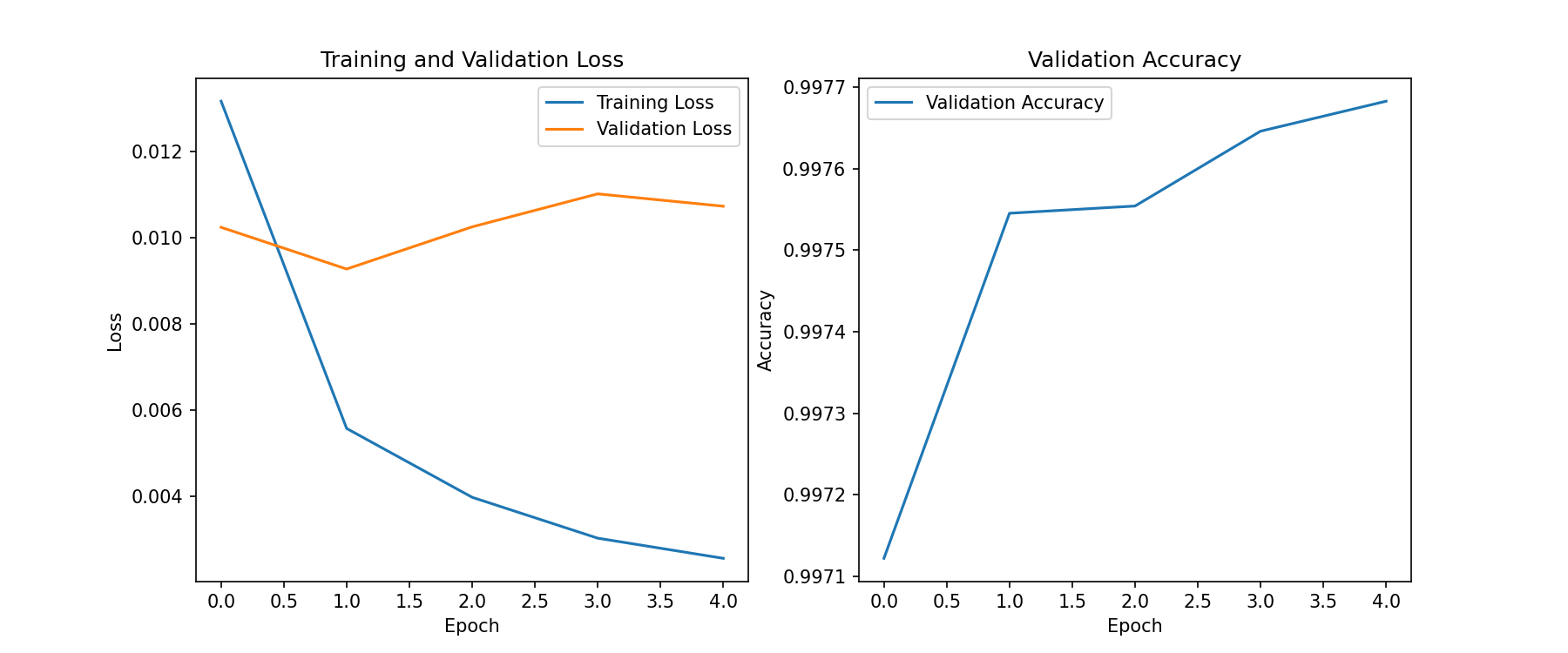
结果分析
实验共进行了5个epoch,从折线图中可以看出,训练数据的损失值一直在下降,但在验证集上的损失值有所波动。验证集上准确率有所提升,提升幅度逐渐放缓。
参考文献
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
- Hugging Face Transformers库:https://github.com/huggingface/transformers
- PyTorch官方文档:https://pytorch.org/docs/stable/index.html
- ChatGPT,辅助完成少量代码和文档。