算法流程描述 首先,对数据集进行预处理。本实验使用scene_categories数据集,该数据集包括15个类别(文件夹名就是类别名),每个类中编号前150号的样本作为训练样本,15个类一共2250张训练样本;剩下的样本构成测试集合。对数据进行SIFT特征提取,得到每张图片的描述符,作为训练数据。
函数功能说明 extract_sift_features 将输入的彩色图像转换为灰度图像,然后使用SIFT算法检测图像中的关键点,并计算这些关键点的SIFT特征描述符。
1 2 3 4 5 def extract_sift_features (image ):None )return descriptors
preprocess_data 对输入的图像路径列表进行预处理,提取每张图像的SIFT特征描述符,并将所有特征描述符拼接成一个特征矩阵返回。
1 2 3 4 5 6 7 8 9 def preprocess_data (img_paths ):for img_path in img_paths:if image is not None :if sift_features is not None :return np.concatenate(features, axis=0 )
build_vocabulary 使用K均值聚类算法对给定的特征集进行聚类,并构建一个视觉词汇,返回聚类中心。
1 2 3 4 def build_vocabulary (features, vocab_size ):return kmeans.cluster_centers_
compute_bovw 根据给定的特征和视觉词汇计算图像的词袋表示,并返回词袋表示。
1 2 3 4 5 6 7 8 9 def compute_bovw (features, vocabulary ):0 ], init=vocabulary, n_init=1 , max_iter=1 )1 , vocabulary.shape[0 ]))if features is not None :for assignment in assignments:0 , assignment] += 1 return bovw_representation
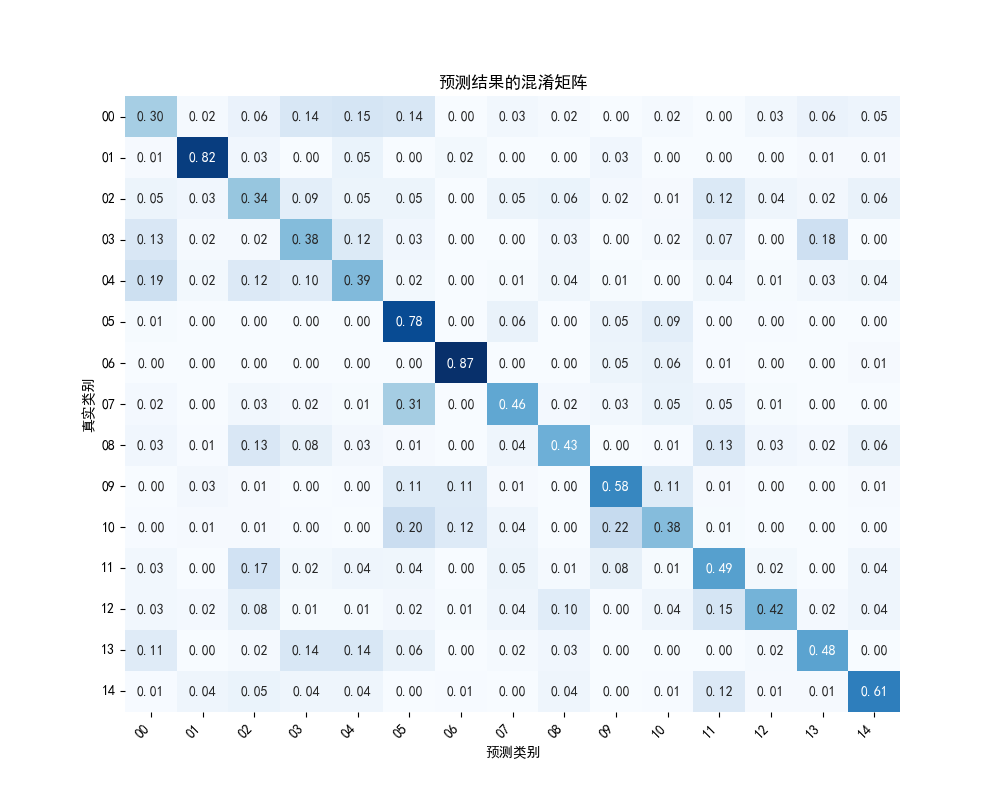
在主函数中,首先按每个类别前150个数据为训练数据的原创对原始数据进行训练集和测试集的划分,然后调用上面的函数进行SIFT特征提取、计算词汇表、计算词袋模型,然后训练svm分类器,对测试数据的词袋表示进行预测,计算预测结果与真实结果的准确率与混淆矩阵,并将混淆矩阵可视化。
数据划分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 for path, dirs, files in os.walk(img_path):for i, file in enumerate (files):if (i < 150 ):else :if (len (files) > 0 ):'/' )[-1 ]] * 150 )'/' )[-1 ]] * (len (files) - 150 ))
训练和测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 print ("正在训练SVM分类器..." )'linear' )for img_path in tqdm(test_img_paths, desc="正在测试分类器" ):0 )print ("准确率:{:.3f}%" .format (accuracy*100 ))
计算并可视化混淆矩阵:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 'float' ) / conf_mat.sum (axis=1 )[:, np.newaxis]'00' , '01' , '02' , '03' , '04' , '05' , '06' , '07' , '08' , '09' , '10' , '11' , '12' , '13' , '14' ]10 , 8 ))True , fmt='.2f' , cmap='Blues' , cbar=False )len (categories))+0.5 )45 , ha='right' )len (categories))+0.5 )0 )'预测类别' )'真实类别' )'预测结果的混淆矩阵' )
函数参数说明 extract_sift_features:image: 输入的图像,是一个三维的NumPy数组,表示为(height, width, channels)。preprocess_data:img_paths: 包含图像文件路径的列表,用于指定要预处理的图像数据集。build_vocabulary:features: 特征矩阵,是一个二维NumPy数组,每行代表一个特征向量。vocab_size: 视觉词汇的大小,即要构建的聚类中心数量。compute_bovw:features: 特征矩阵,是一个二维NumPy数组,每行代表一个特征向量。vocabulary: 视觉词汇,是一个二维NumPy数组,每行代表一个聚类中心。
结果分析 在实验中发现,适当增大vocab_size可以带来更高的准确率,但考虑设备性能,最终选择的值为3000。
预测结果的混淆矩阵如下,其中每行之和为1,每个元素为预测类别在帧数类别中所占比例: